
LOGIN AND CHOSE COLLECTION
Once you installed and opened Transkribus platform, log into it using the login button on the upper left panel. Remember: your username is the email address you registered with.
The next step is to chose the collection you are working on. The default will be your own private collection, but you can also create collections. No one has access to the content of your collections unless you share them, using the ‘User manager’ button. To select a different collection, double click the collections button.
UPLOAD
To upload your documents, use the import button on the upper ruler:
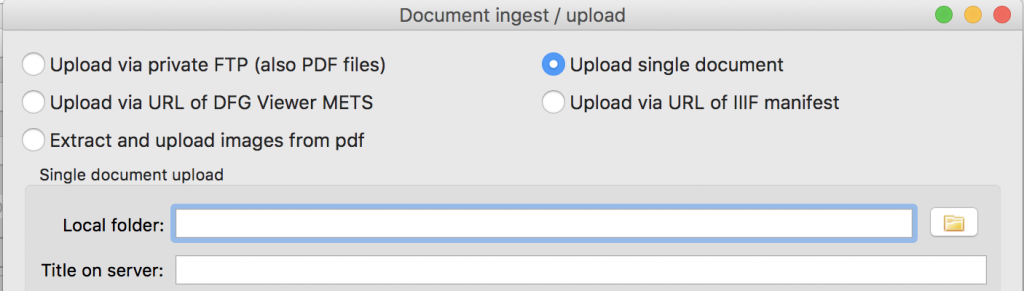
You can upload PDF, JPEG, PNG and TIFF files. For Pdf upload: select a pdf file.
Single document upload: select a folder with image files in it – they will be combined into one document.
You may rename the file with an informative title and re-select the collection you wish to upload the document into. Then press Upload.
ANALYSE PAGE LAYOUT
Before you can transcribe, or let Transkribus try to recognize the text for you, you have to first analyse the layout of the pages you uploaded: text regions and lines. you do this in the Tools tab – the fifth option on the left panel.
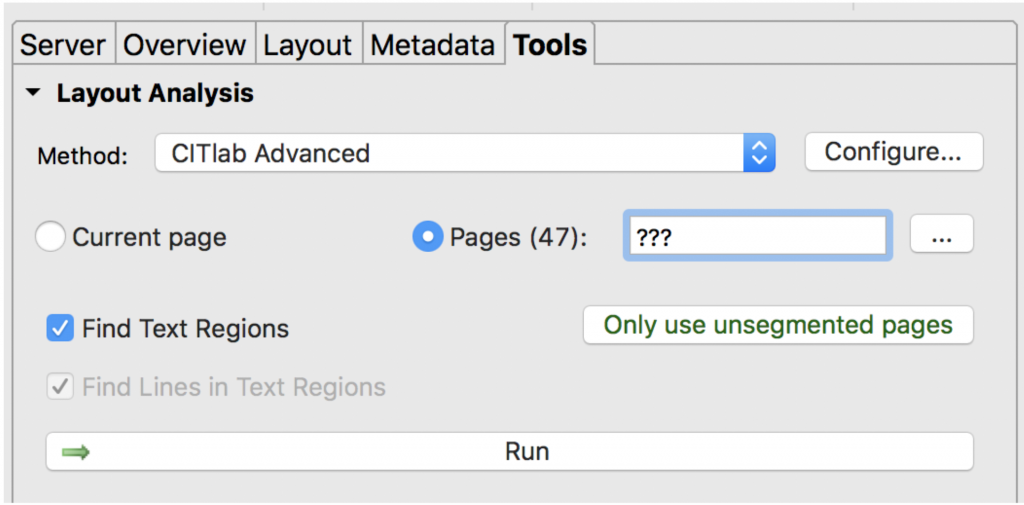
Layout Analysis can be very simple when your sources are regular book pages: Just select the pages you wish to analyse and run. It might take a minute, and you will get a pop up window when the job is done and you can then refresh to see the result: a page analysed for text region(s), lines and baseline (the lower base of the main text in the line).
If, however, your sources have columns and other text blocks, chose the alternative method: Printed Block detection, run, and then go back to the default method (CITLab advanced), unclick the ‘find text regions’ button, and rerun to have the lines detected.
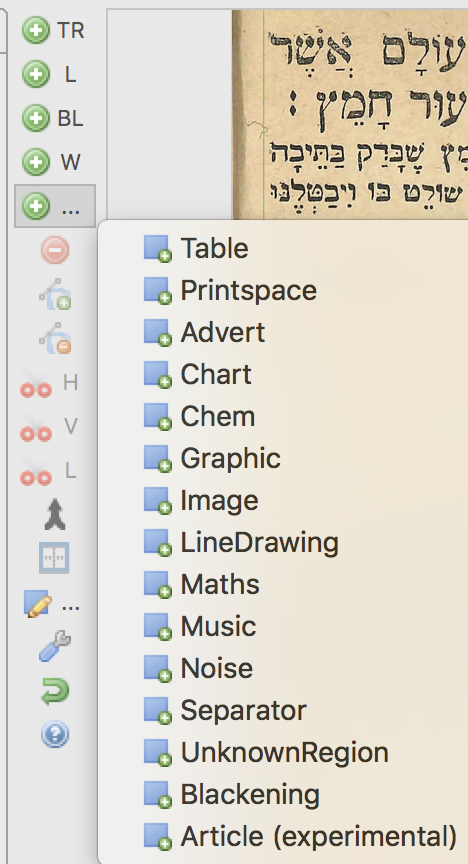
Layout may often need manual correction and specification. This can be done in the left ruler, which enables drawing and defining Text regions, base lines and many other structure types. You can also edit the layout manually on the screen. For fuller guidelines see the Transkribus documentation.
Alternatively, watch the short video demonstrations here. You can also approach the helpful community of Transkribus users in the facebook group.
TEXT RECOGNITION:
you are finally ready to let the computer try and read your text. This is also done in the ‘tools’ panel, under ‘text recognition’. Just press run!
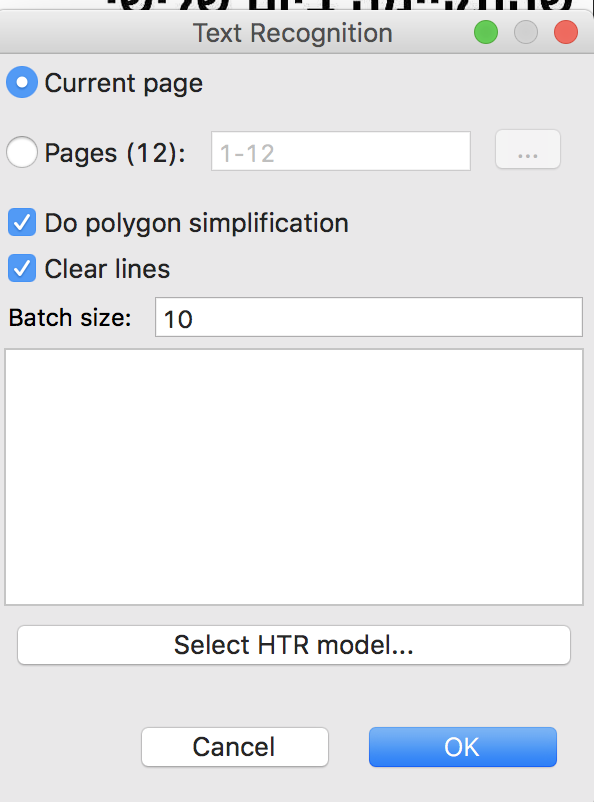
You now have to select the pages you wish to ‘read’ and by clicking “Select HTR model”, select the model that can read them. For Hebrew letters that are in use in Jewish languages, we prepared the model “DiJeSt for Hebrew Script Languages”; read more about it here. After selecting it click OK, then OK again, and wait. It can take up to 30 seconds per page. before you will get a notice that you can refresh the page and see the results.
CORRECT, SEARCH, EXPORT:
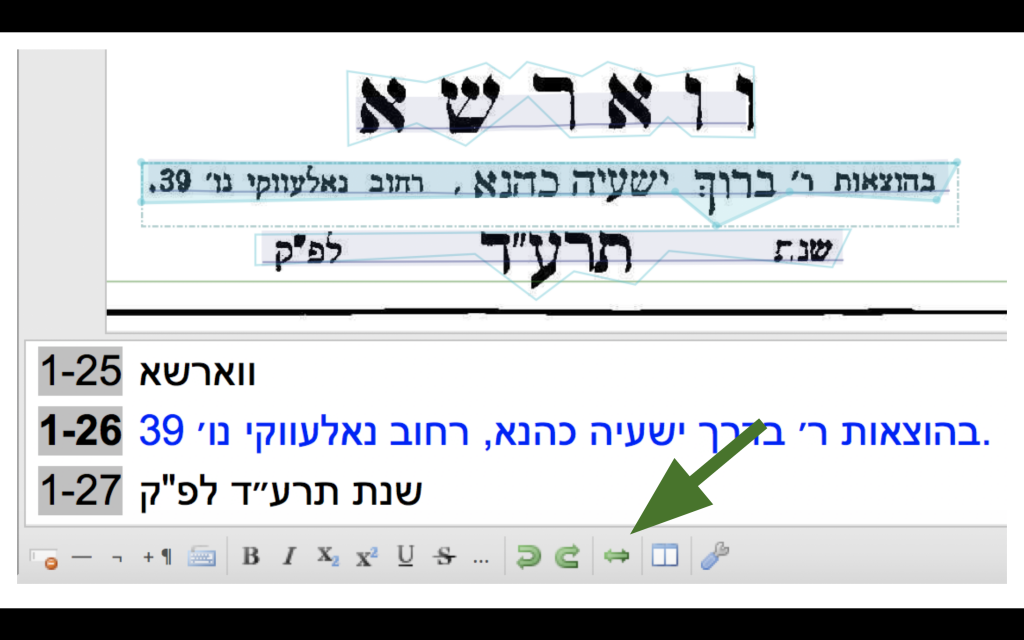
Transkribus enables correcting the text in the transcription panel under the picture of the page. You will notice that as default, the text is aligned to the left. In order to align it to the right, use the double-sided arrow at the bottom ruler:
Transkribus enables searching your data and retrieving results in text, even if they were not corrected (using the fuzzy search or KWS method).
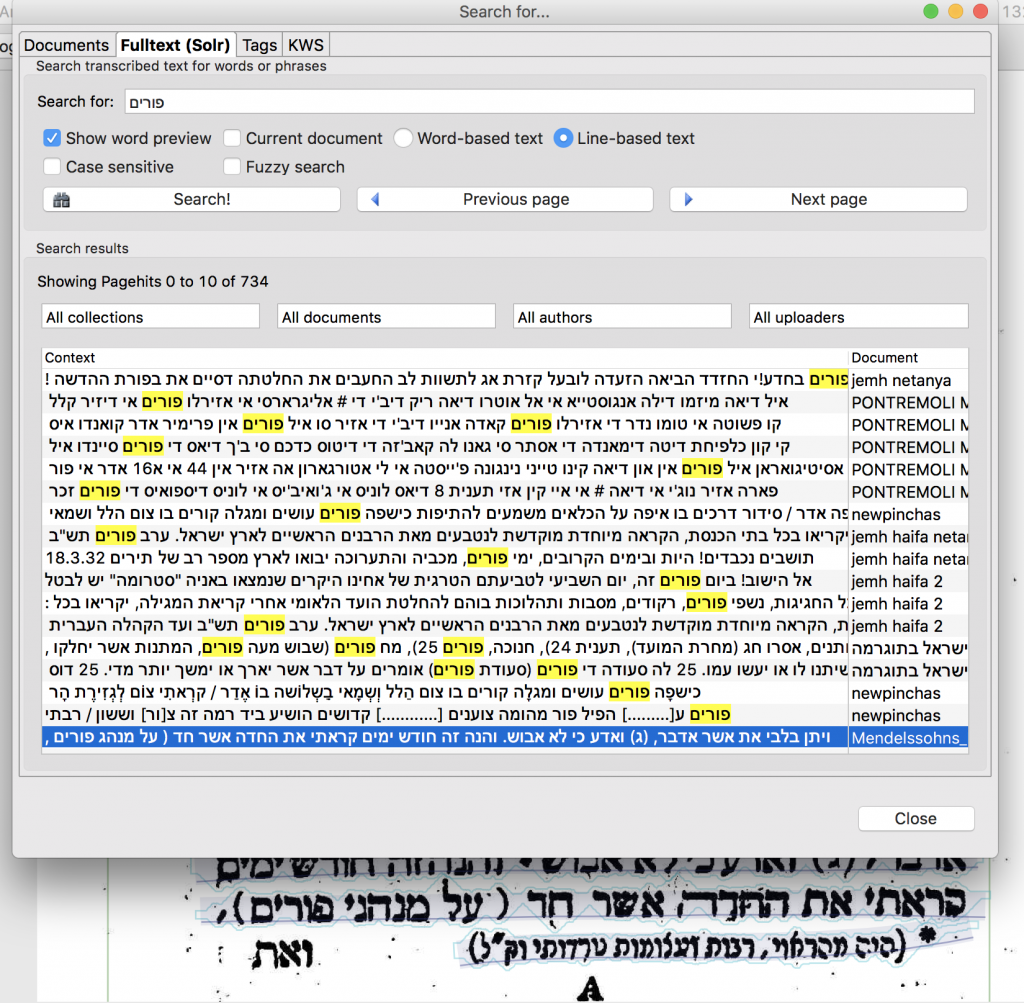
Look for the small binoculars in the upper ruler to explore these functions.
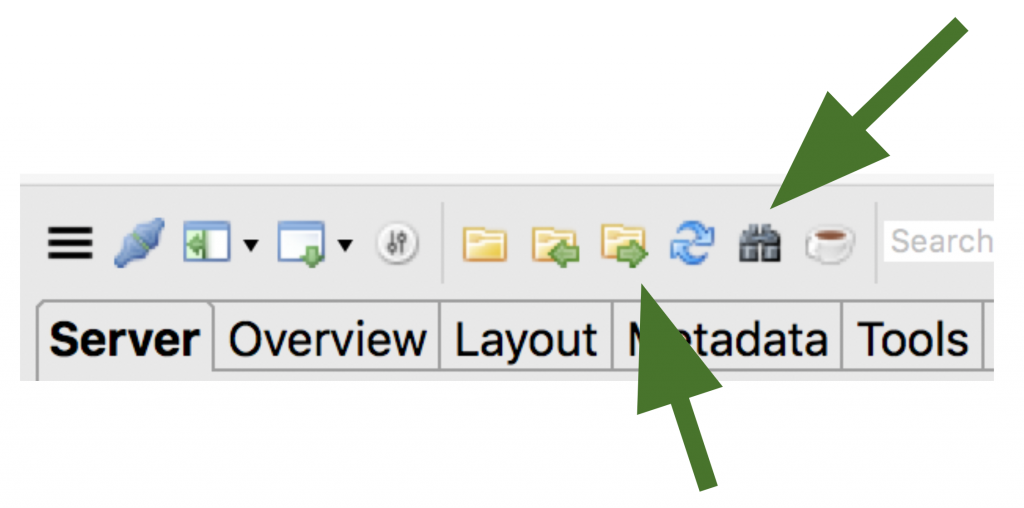
Finally (using the symbol that the bottom arrow points to) you can export your documents. The server export will deliver the file to your email; the client export will download it to your computer. There are several format options to chose from. The .DOCX option, alas, is not working yet for right-to-left languages (but Transkribus team promised that they are working on it!), but you can export as plain text files, XML-TEI or pdf, and even include in the PDF extra pages with the deciphered text:
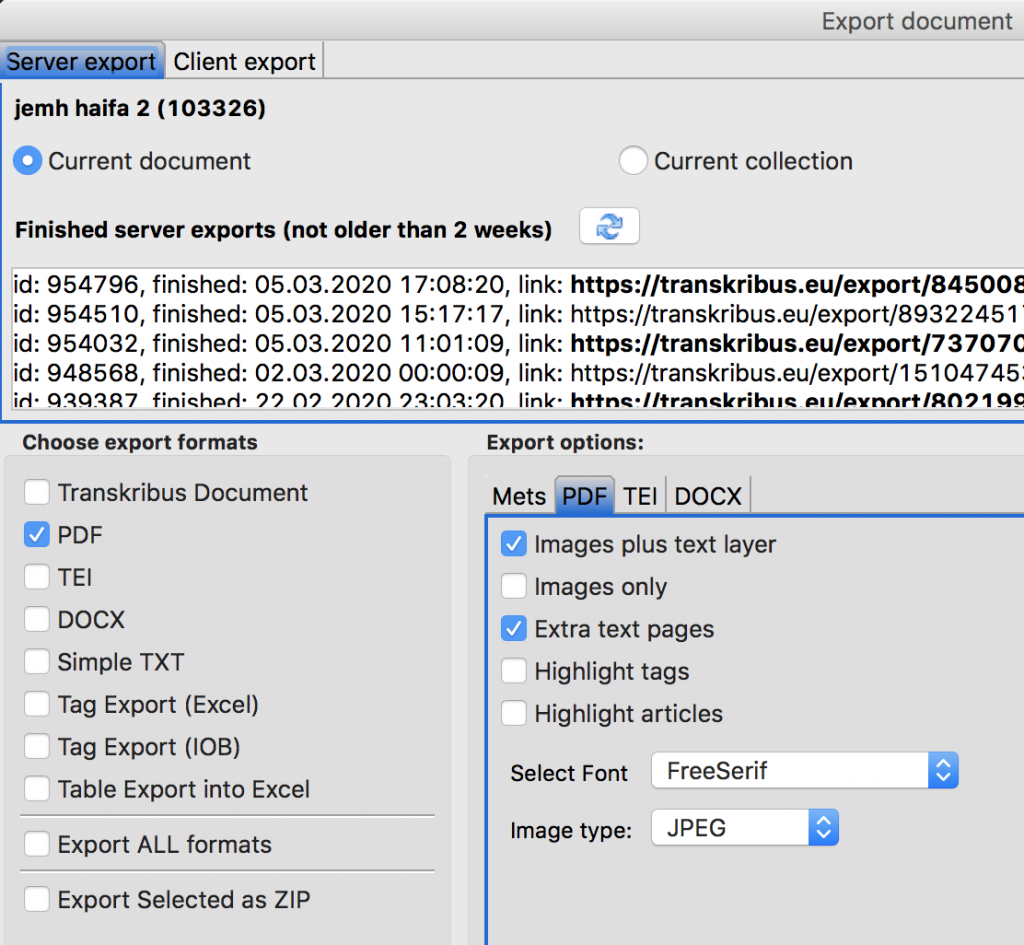
Press OK, and in a short time you will have the outcome of your work.
There are many more things to do with Transkribus: annotate and enrich text and metadata, edit structure, compare and measure versions and ocr accuracy and train your own models for layout and text recognition. For these, consult Transkribus’ documentation, and if this doesn’t work, the facebook user group or transkribus team.
The one last button that I would still like to introduce to you here is the cup of coffee:

If you run an automated job, whether layout analysis, text recognition, accuracy checks, keyword spotting or training, the job may take time. Whether 20 seconds or several hours (which might be the case for training a model), you can always press the coffee mug and see the status of the jobs you run. Or move to work on other documents. Or have a break, be patient, and remember how long it would have taken your to do this all by hand.